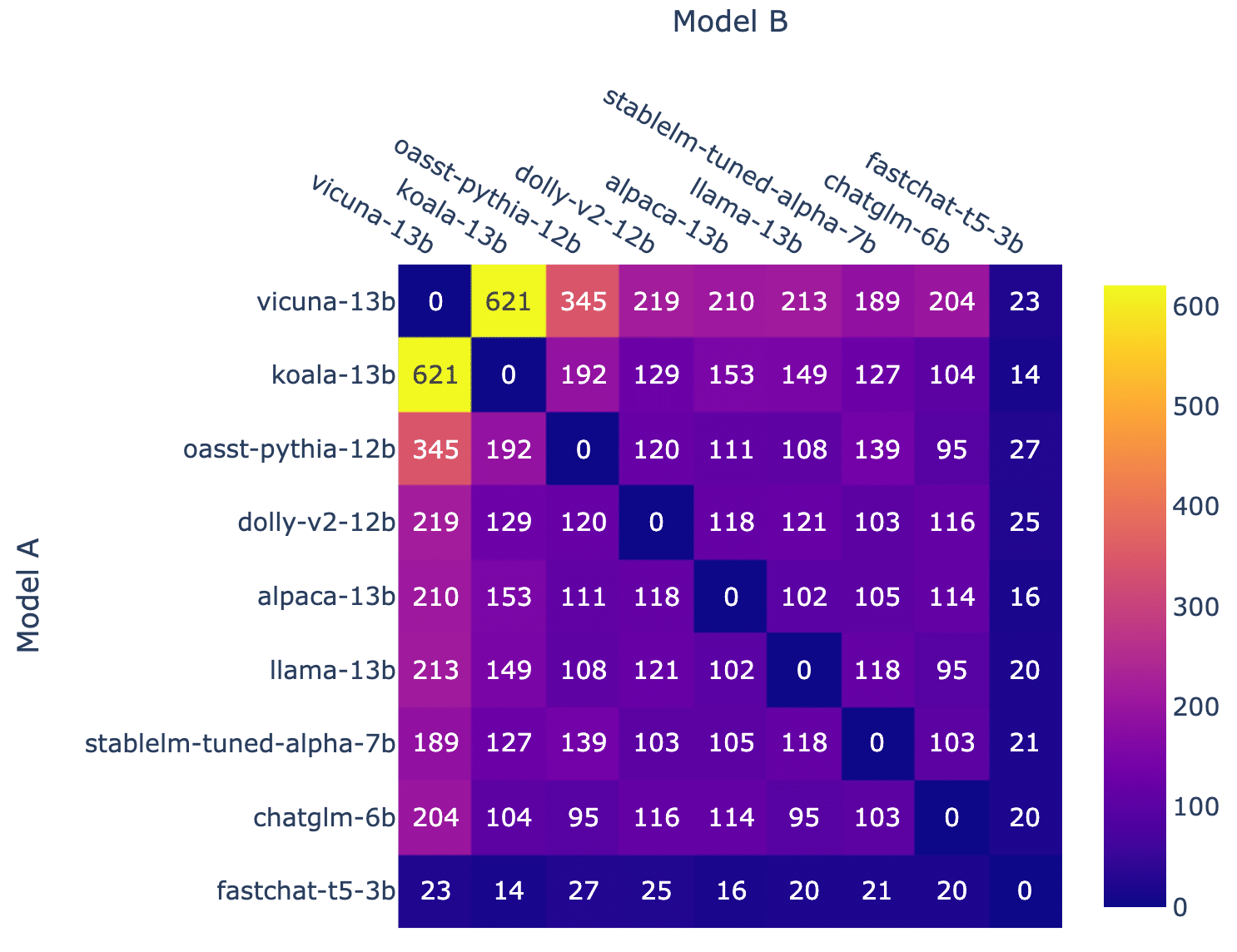
Un artículo académico publicado por investigadores de Cohere, Stanford, MIT y Ai2 expone presuntas irregularidades en Chatbot Arena, el benchmark líder para evaluar modelos de inteligencia artificial. Según el estudio, LM Arena, entidad detrás de la plataforma, habría permitido a Meta, OpenAI, Google y Amazon probar múltiples variantes de sus modelos en privado, ocultando los resultados menos favorables para posicionarse mejor en el ranking público.
Ion Stoica, cofundador de LM Arena, calificó el estudio de «lleno de inexactitudes» en un comunicado. La organización defendió su método de evaluación y destacó que «la comunidad puede someter más modelos para mejorar su rendimiento».

El diseño modular de Chatbot Arena, que compara respuestas de IA en tiempo real, enfrenta cuestionamientos sobre su transparencia. Los autores exigen:
La tipografía digital utilizada en los informes técnicos contrasta con la opacidad denunciada. Este caso resurge tras el escándalo de Meta con Llama 4, donde un modelo optimizado para el benchmark no fue lanzado al público.


