
Al hablar del costo de la infraestructura de inteligencia artificial, el foco suele estar en Nvidia y las GPUs, pero la memoria se ha convertido en una parte cada vez más crítica del panorama. Mientras los hiperescalares se preparan para construir centros de datos por valor de miles de millones de dólares, el precio de los chips DRAM ha aumentado aproximadamente 7 veces en el último año.
Surge una disciplina creciente en orquestar toda esa memoria para asegurar que los datos correctos lleguen al agente correcto en el momento preciso. Las empresas que la dominen podrán realizar las mismas consultas con menos tokens, lo que puede marcar la diferencia entre fracasar o mantenerse en el negocio.
El analista de semiconductores Dan O’Laughlin y Val Bercovici, director de IA de Weka, destacan la importancia de los chips de memoria. Bercovici señala la creciente complejidad en la documentación de cacheo de prompts de Anthropic como un indicador clave.
«El indicador es si vamos a la página de precios de cacheo de prompts de Anthropic. Comenzó siendo una página muy simple hace seis o siete meses… Ahora es una enciclopedia de consejos sobre exactamente cuántas escrituras en caché precomprar.»
Anthropic ofrece ventanas de cacheo de 5 minutos o de 1 hora, siendo más económico acceder a datos que aún están en la caché. Una gestión eficiente puede generar ahorros significativos, pero con una salvedad: cada nuevo dato añadido a la consulta puede desplazar algo más de la ventana de caché.

La gestión de memoria en modelos de IA será una parte enorme del futuro del sector. Empresas como la startup TensorMesh trabajan en capas de la pila como la optimización de caché. Existen oportunidades en otros niveles: desde el uso de diferentes tipos de memoria en centros de datos (como DRAM frente a HBM) hasta cómo los usuarios finales estructuran sus enjambres de modelos para aprovechar la caché compartida.
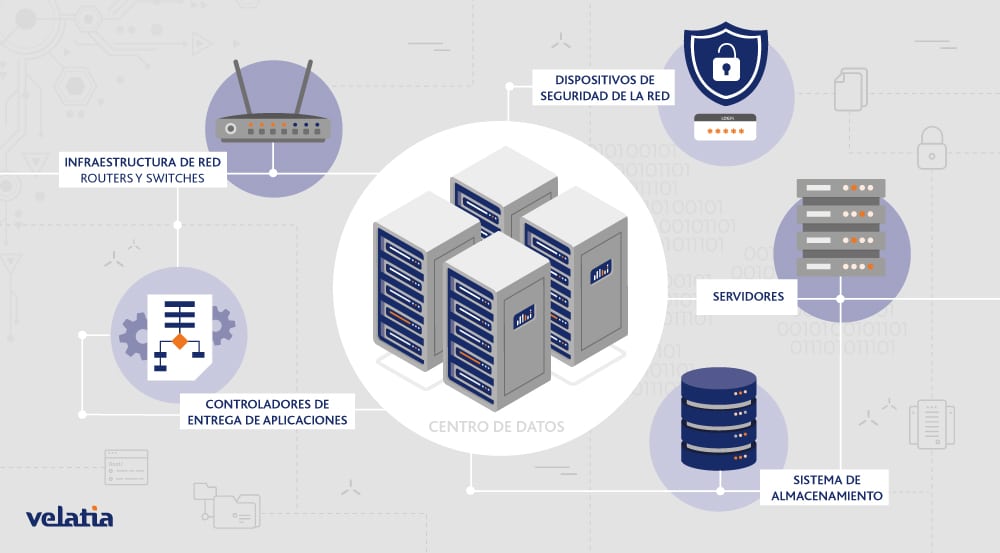
A medida que las empresas mejoren en la orquestación de memoria, usarán menos tokens y la inferencia se abaratará. Simultáneamente, los modelos se vuelven más eficientes en el procesamiento por token, reduciendo costos aún más. Con la caída de los costos de servidores, muchas aplicaciones que hoy no parecen viables comenzarán a acercarse a la rentabilidad.
En resumen, dominar la gestión de memoria no es solo un tema técnico, sino un imperativo económico para las empresas de IA que buscan liderar en un mercado cada vez más competitivo.


